

At Freeday we already showed how AI predicts CSAT for 100% of conversations, even the ones that never get a survey click. That system gives us a predicted 1–5 score plus a short explanation for many conversations that would otherwise be silent. CSAT is our compass, because it tells us directly how satisfied users are, and higher CSAT is strongly linked to loyalty and retention.
But CSAT alone doesn’t always tell the full story. It’s still an outcome. To truly improve we need to understand the why. A conversation might end with a low satisfaction score: was the assistant too formal, unclear, off-topic, or unhelpful when something went wrong?
That’s where the Freeday Conversation Principles come in.
This framework lets us assess how our digital employees communicate, focusing on empathy, clarity, understanding, and more. Together with CSAT, it gives us both the outcome and the explanation behind it.
Measuring the quality of communication in conversations has always been tricky. We already had CSAT to show whether users were satisfied, but CSAT doesn’t always pinpoint what needs to be improved.
Imagine your digital employee finishes a conversation and the CSAT prediction comes back as 2 out of 5. You know the user wasn’t happy, but why not? Was the assistant unclear in its answers? Too formal in tone? Did it misunderstand the request?
Manual reviews using the Conversation Principles could, in theory, answer those questions. But going through thousands of conversations per day by hand is slow, inconsistent, and not scalable.
This left us with three main challenges:
To keep raising satisfaction, we needed a way to measure how conversations were being handled; reliably, consistently, and at scale.
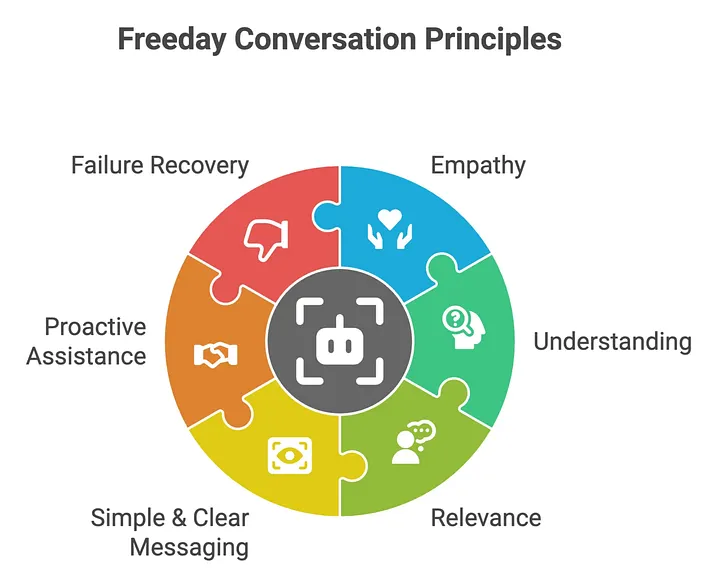
To go beyond CSAT and understand why conversations succeed or fail, we created the Freeday Conversation Principles: a practical framework for evaluating and improving how our digital employees interact with users.
Rather than just providing correct answers, our digital employees should be: clear, relevant, empathetic, and helpful. Each principle focuses on a key element of great communication. By applying these principles, we can not only measure but also consistently raise conversation quality at scale
The six principles are:
Together, these principles help our digital employees not just answer questions, but deliver meaningful, human-like experiences that feel natural, helpful, and reliable.
Every conversation is scored on the six principles using a structured scorecard, the same kind of approach that’s commonly used to evaluate real customer support agents. Each evaluation returns:
The score itself isn’t a final verdict, the explanation is what makes it actionable. If the evaluator can justify their judgment in a clear, human-like way, the score becomes meaningful; if not, we refine the scoring rubric and alignment.
Using this scorecard approach gives us three key advantages at scale:
Customer: “I can no longer log in to my account.”
Digital Employee: Provides instructions for password reset, email/phone re-verification, and 2FA issues.
Customer: “I’ve already tried all of that.”
Digital Employee: Escalates to a human agent: “I’m forwarding your request to a team member. You’ll receive a reply within 24 hours.”
Principles:
Action: Adjust the flow to include a short acknowledgment of frustration or repeated attempts before escalating. For example:
“I see you’ve already tried these steps. I understand that must be frustrating. I’m forwarding your request to a team member who will follow up shortly.”
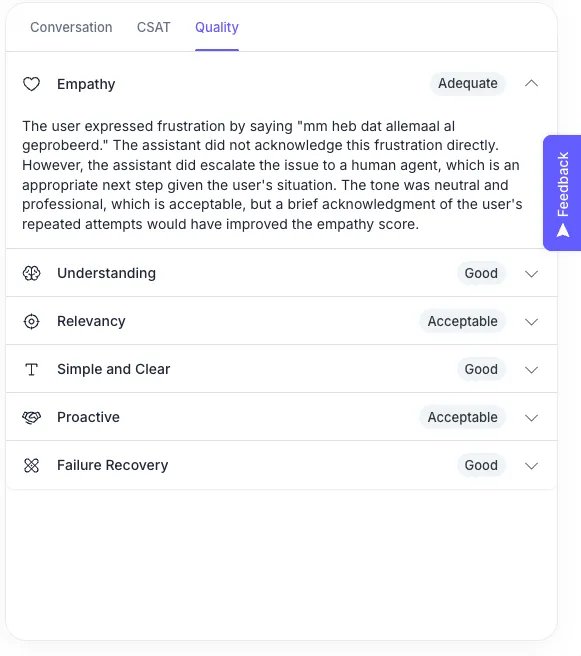
To make principle scores actionable, we surface them in the our portal using a simple traffic-light logic:
When AI-CSAT is low, the principle scores and their explanations highlight the root cause. And when a principle trends red across a flow, CSAT erosion usually follows, a clear signal for product or content improvements.
Clients get a quick overview via the traffic-light dashboard, and can drill down into individual conversations to see why a principle (like Understanding) scored low.

✅ Measure conversation quality like you measure agent performance, for every digital employee, every conversation.
✅ Link communication problems to CSAT.
✅ Prioritize the fixes that actually affect customer experience.
✅ Run experiments and track principle scores to validate whether a change improved how we talk, not just what we achieved.
We’re now focusing on closing the feedback loop: giving clients the tools to act on issues themselves, from refining phrasing to improving missing content in their knowledge base.
Even at this stage, the Conversation Principles system gives us something new:
A clear, actionable, human-centered way to measure how conversations succeed or fail, not just whether they do.
This isn’t a nice-to-have. It’s a step toward a new standard in customer support, where quality is visible, measurable, and improvable.
At Freeday, we’re not just adapting to that future, we’re helping shape it, and we’ll keep sharing what we learn along the way.
